
In my original version of this post, I did not link to the article this post references to protect the competitor and their customer. But then Yugabyte posted trumped up performance numbers, comparing their current release (July 2025) to a four year old CockroachDB release (November 2021). So I wrote about the original post, which had by that time been removed from the internet. When I have quotes around something, as I have in the next paragraph when I write "database snake oil", that something comes directly from the original article. I'm going to keep this post as originally written, but with the clarity that naming companies brings, and I suggest you read the post linked above first to get context.
In this article, I try to read the minds of those involved to understand how they got where they did, running a solution that's not even in the Gartner MQ.
Recently a company, a popular company [Cursor], using one of my competitors [Yugabyte] had a massive outage. In response, Cursor reverted from distributed SQL and declared that anything other than straight Postgres is "database snake oil" spewed by vendors inventing problems. They declared as an absolute truth: "database vendors optimize for their revenue, not your success."
I think Postgres is a great solution, but let's be clear, just because one company had an outage (this is the Cursor point of view; we don't know Yugabyte's point of view on the outage) doesn't negate the promises of entire sub-genre of database solutions, that of distributed SQL ($ Gartner).
I originally didn't want to share the article that discussed the situation because we don't have the vendor's point of view (though as mentioned above, I now have shared it). I'm more interested in Cursor's broad vilification of the distributed SQL space. Follow my train of thought if you will as to how this situation likely evolved.
The Open Source Situation
Cursor said they chose their particular solution because Yugabyte promised "infinite scalability". (It turns out infinite means ~170 nodes in a cluster, as shared by Shopify on this slide. Shopify may not be their largest cluster, but looks like they're definitely one of the largest.)

I know for a fact that we weren't involved in a competitive bake-off for this opportunity. And, considering that we're the leading distributed SQL company in the Gartner Magic Quadrant ($) it's unlikely that non-open source solutions were examined. Open source is compelling – you can get started so quickly! – until you suffer a massive outage and look to blame the vendor.
What's more likely to have happened is that they had an idea – let's use distributed SQL to help us scale – and then downloaded some free software and started using it. I'm sure testing was done, but how much testing? And, on what vectors was it tested? Performance? Scale? Simplicity of ownership? Quality of support? Postgres compatibility? Resilience?
Here at Cockroach Labs we've tested AND, as of 25.4 delivered in November 2025, support clusters at 300 nodes with 1 petabytes of data.
From a performance perspective, in internal testing we out-performed them even before we improved performance by 50% earlier this year.
Did this customer do the right due diligence, or did they first filter on 'open-source' and then pick the remaining option? Were they moving so quickly that it was more ready, fire, aim than careful planning? It sure sounds like it.
"Compatibility isn't the same as reliability"
That's a quote from the article. And, Postgres compatibility is one of Yugabyte's key selling points. (Notice, I said "key" not "unique.")
The thing I'd infer by this point made in the post is that Postgres compatibility was very important to this customer.
Perhaps they believed the marketing around compatibility (as compared to CockroachDB) the same way they believed the marketing around "infinite scalability"?
We can argue all we want about compatibility; my two points are:
- We're effectively equal in compatibility when it comes to what matters (in spite of a fake "compatibility index" that's floating around out there). For example, you might say "CockroachDB doesn't support extensions and so isn't compatible with the world of Postgres extensions." My argument would be that those are two different things. No, we don't support extensions. But that's because we rewrite the things we need into our SQL layer to ensure compatibility with the underlying distributed layer (pgvector is a great example of this approach). It's more work for us, but maybe that's why we don't have the failures that our competitor does trying to stitch together a layer that's unaware of the distributed underpinnings with the distributed underpinnings! It is why it's taken us longer to deliver on stored procedures, user defined functions, and some other features - so the compatibility argument might have held more water in past years, but certainly is no longer the case. That said, it's a good area to test in a competitive bake-off to make sure you get what you need, because no product is 100% Postgres compatible.
- Even if you don't believe me on compatibility, I'd ask that you suspend your disbelief (until you're ready to comparison test... and then test away!). We're lots more resilient than this competitor. How do I know? Well, we've created a benchmark that measures resilience and, again, done some internal testing to explore relative performance. Frankly, we make this resilience stuff look easy until you look at competitive benchmarks... and realize it's not.
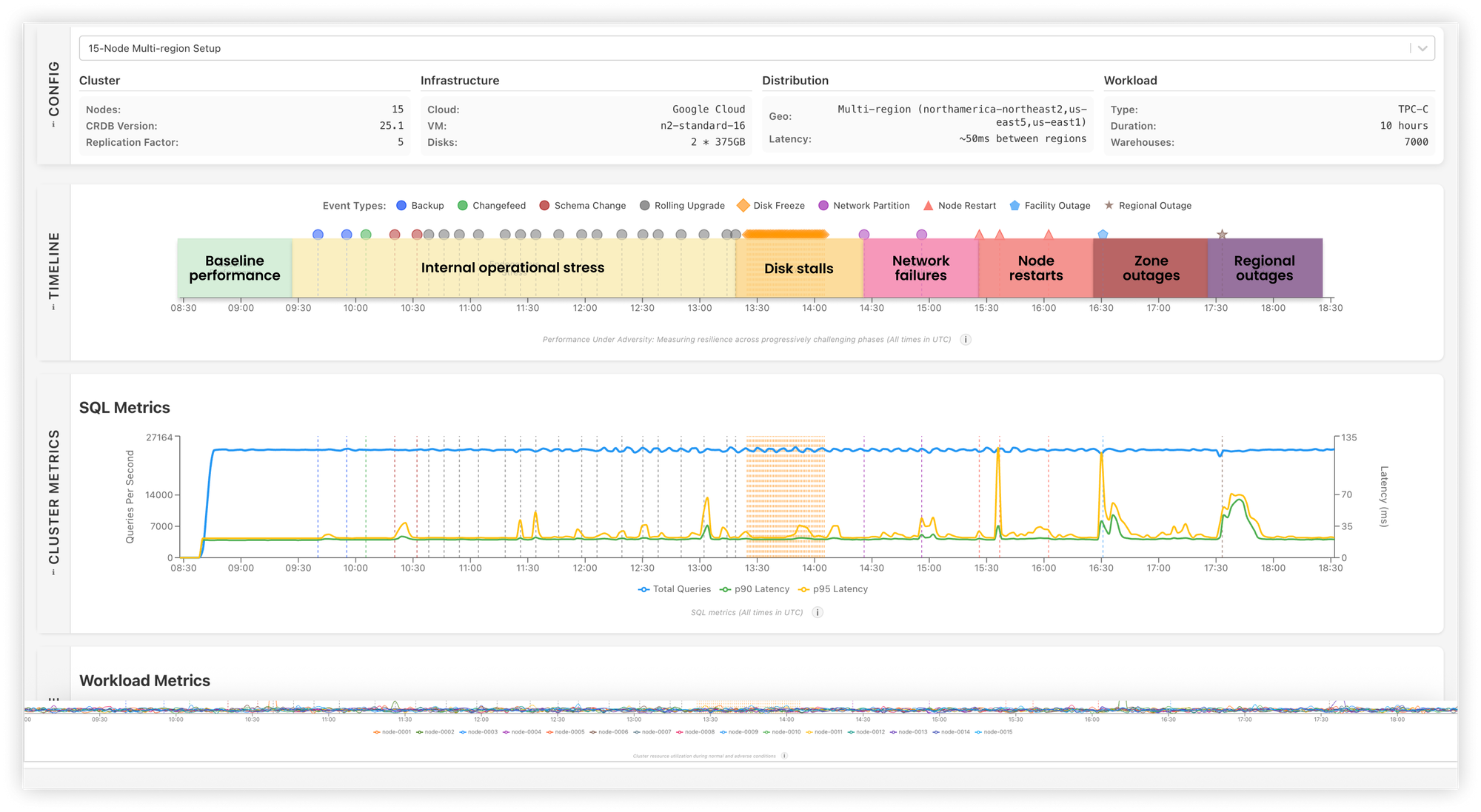
The reality appears to be that we released this resilience benchmark after the customer already adopted this competitor. But going forward, companies don't have an excuse. Not only are we updating this benchmark with each release of CockroachDB, we share documentation on how to recreate the benchmark on your own so you can experience the results in your environment. There's really no excuse anymore not to test resilience (or Postgres compatibility) as part of any distributed SQL proof-of-concept evaluation.
"Start with PostgreSQL and change when you hit its limits"
Who doesn't love a good database migration?
Not me, that's for sure. Migrations are hard. And worse, they're risky and disruptive.
If Postgres is hitting the ceiling for your mission-critical workloads, the next step isn't endless ops work – it's embracing distributed SQL (from SumUp case study)
If Postgres meets your needs, and your planned needs, go for it. It's a great solution. In fact, earlier today we were talking about a prospect's workload tests and decided that for this particular opportunity we should bow out because the workload is too small to take advantage of the benefits of distributed SQL. A single database is always going to be faster; distributed SQL is better when you need more resilience and / or scale than a single database can provide. There are other advantages, such as simplicity of management and data placement... but the main benefits are resilience and that every node in a distributed SQL database can read and write, so if you need more scale, you just add more nodes (just not an infinite number of nodes as some vendors seem to promise).
And, choosing a distributed database gives you architectural flexibility as well. It has the ability to evolve into any architecture you need. Want to start with serverless, migrate to a cloud-only solution, then move to multi-cloud for reslience? You can. Want to start on-prem, move to hybrid, then go multi-cloud? Simple. You might not need multi-cloud resilience, but with regulations like DORA coming into play, it's best to have a database that gives you all the architectural flexibility you can imagine.
With CockroachDB specifically, if you want to start serverless, you can start with CockroachDB Basic. If you outgrow that (or need some of the enterprise security capabilities offered by other tiers), you simply switch to one of our other cloud tiers, or can easily repatriate the data to your own data centers (or your own cloud) and run it yourself without the need to migrate data between databases.
Conclusion
Finally, distributed SQL is a step forward in the evolution of transactional databases. In fact, I'm still surprised every time I hear of a NoSQL user trying to figure out how to get transactional integrity in their database because they need the scale of NoSQL and also the transactional integrity of something like Postgres. The answer is distributed SQL.
The benefits of distributed SQL are too hard to ignore if they're right for your workload, even if you're not quite there yet. These benefits include:
- Resilience
- Scale
- Data placement / geo-data governance
- Simplified cost of ownership
- Eliminated planned downtime for upgrades and schema changes
It doesn't make any sense at all to turn the experience with one vendor, one that even Gartner doesn't track anymore, into a broad vilification of an entire database sub-genre.
Get started with CockroachDB Cloud
Spin up your first CockroachDB Cloud cluster in minutes. Start with $400 in free credits.